Целью проекта являлась разработка новых алгоритмов для неблокирующих и разреженных коллективных операций стандарта MPI.
Неблокирующие и разреженные коллективные операции были добавлены в версии 3 MPI стандарта. На текущий момент MPI реализации с открытым исходным кодом (MPICH*, Open MPI*) содержат малое количество алгоритмов для этих типов коллективных операций.
Необходимо было решить следующие задачи:
-
Исследование существующего набора алгоритмов неблокирующих и разреженных коллективных операций.
-
Разработка новых алгоритмов и оценка их производительности.
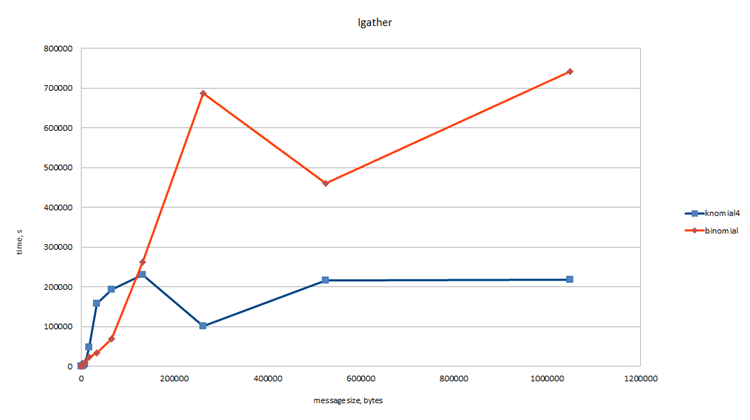
Были разработаны алгоритмы для функций MPI_Iallreduce, MPI_Bcast, MPI_Ireduce, MPI_Igather, MPI_Iscatter, MPI_Ineighbour_alltoall.
Разработанные knomial алгоритмы для коллективных операций предпочтительней использовать, когда количество процессов кратно knomial-factor'у.
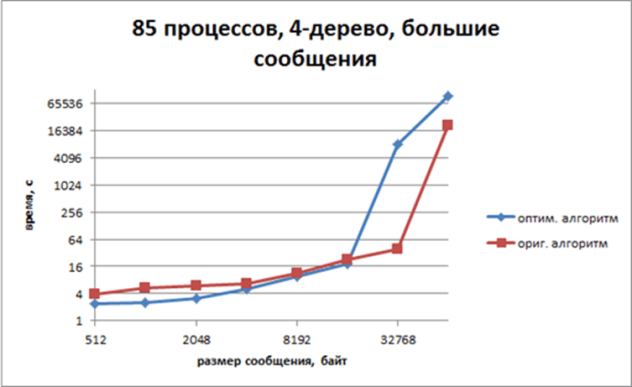
Разработаны и исследованы тестовые методы для оптимизации локальных обменов на топологии k-дерева. Тестирование показало, что данное преобразование структуры обменов уменьшает время выполнения тестов для небольших размеров сообщений, на больших размерах сообщения алгоритм начинает проигрывать стандартному.
Исследованы методы оптимизации для декартовых топологий. Оптимизация позволяет получить ускорение относительно стандартного алгоритма MPICH на средних размерах сообщения от 512 до 1024 байт, c увеличением количества процессов ускорение возрастает.